
You are currently browsing the tag archive for the ‘regularity lemma’ tag.
Szemerédi’s theorem asserts that all subsets of the natural numbers of positive density contain arbitrarily long arithmetic progressions. Roth’s theorem is the special case when one considers arithmetic progressions of length three. Both theorems have many important proofs using tools from additive combinatorics, (higher order) Fourier analysis, (hyper) graph regularity theory, and ergodic theory. However, the original proof by Endre Szemerédi, while extremely intricate, was purely combinatorial (and in particular “elementary”) and almost entirely self-contained, except for an invocation of the van der Waerden theorem. It is also notable for introducing a prototype of what is now known as the Szemerédi regularity lemma.
Back in 2005, I rewrote Szemerédi’s original proof in order to understand it better, however my rewrite ended up being about the same length as the original argument and was probably only usable to myself. In 2012, after Szemerédi was awarded the Abel prize, I revisited this argument with the intention to try to write up a more readable version of the proof, but ended up just presenting some ingredients of the argument in a blog post, rather than try to rewrite the whole thing. In that post, I suspected that the cleanest way to write up the argument would be through the language of nonstandard analysis (perhaps in an iterated hyperextension that could handle various hierarchies of infinitesimals), but was unable to actually achieve any substantial simplifications by passing to the nonstandard world.
A few weeks ago, I participated in a week-long workshop at the American Institute of Mathematics on “Nonstandard methods in combinatorial number theory”, and spent some time in a working group with Shabnam Akhtari, Irfam Alam, Renling Jin, Steven Leth, Karl Mahlburg, Paul Potgieter, and Henry Towsner to try to obtain a manageable nonstandard version of Szemerédi’s original proof. We didn’t end up being able to do so – in fact there are now signs that perhaps nonstandard analysis is not the optimal framework in which to place this argument – but we did at least clarify the existing standard argument, to the point that I was able to go back to my original rewrite of the proof and present it in a more civilised form, which I am now uploading here as an unpublished preprint. There are now a number of simplifications to the proof. Firstly, one no longer needs the full strength of the regularity lemma; only the simpler “weak” regularity lemma of Frieze and Kannan is required. Secondly, the proof has been “factored” into a number of stand-alone propositions of independent interest, in particular involving just (families of) one-dimensional arithmetic progressions rather than the complicated-looking multidimensional arithmetic progressions that occur so frequently in the original argument of Szemerédi. Finally, the delicate manipulations of densities and epsilons via double counting arguments in Szemerédi’s original paper have been abstracted into a certain key property of families of arithmetic progressions that I call the “double counting property”.
The factoring mentioned above is particularly simple in the case of proving Roth’s theorem, which is now presented separately in the above writeup. Roth’s theorem seeks to locate a length three progression 
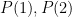
More specifically, Roth’s theorem is now deduced from
Theorem 1.5. Let
be a natural number, and let
be a set of integers of upper density at least
. Then, whenever
and a family
of 3-term arithmetic progressions with the following properties:
- For each
,
and
lie in
- For each
lie in
- The
are in arithmetic progression.
The situation in this theorem is depicted by the following diagram, in which elements of 


Theorem 1.5 is deduced in turn from the following easier variant:
Theorem 1.6. Let
- For each
- For each
- The
The situation here is described by the figure below.

Theorem 1.6 is easy to prove. To derive Theorem 1.5 from Theorem 1.6, or to derive Roth’s theorem from Theorem 1.5, one uses double counting arguments, van der Waerden’s theorem, and the weak regularity lemma, largely as described in this previous blog post; see the writeup for the full details. (I would be interested in seeing a shorter proof of Theorem 1.5 though that did not go through these arguments, and did not use the more powerful theorems of Roth or Szemerédi.)
A few years ago, Ben Green, Tamar Ziegler, and myself proved the following (rather technical-looking) inverse theorem for the Gowers norms:
Theorem 1 (Discrete inverse theorem for Gowers norms) Let
and
be integers, and let
. Suppose that
is a function supported on
such that
Then there exists a filtered nilmanifold
of degree
and complexity
, a polynomial sequence
, and a Lipschitz function
of Lipschitz constant
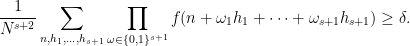

For the definitions of “filtered nilmanifold”, “degree”, “complexity”, and “polynomial sequence”, see the paper of Ben, Tammy, and myself. (I should caution the reader that this blog post will presume a fair amount of familiarity with this subfield of additive combinatorics.) This result has a number of applications, for instance to establishing asymptotics for linear equations in the primes, but this will not be the focus of discussion here.
The purpose of this post is to record the observation that this “discrete” inverse theorem, together with an equidistribution theorem for nilsequences that Ben and I worked out in a separate paper, implies a continuous version:
Theorem 2 (Continuous inverse theorem for Gowers norms) Let
. Suppose that
is a measurable function supported on
such that
Then there exists a filtered nilmanifold
, and a Lipschitz function


The interval 



It is likely that one could prove Theorem 2 by carefully going through the proof of Theorem 1 and replacing all instances of 

![{\frac{1}{N} \cdot [N]}](https://s0.wp.com/latex.php?latex=%7B%5Cfrac%7B1%7D%7BN%7D+%5Ccdot+%5BN%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)



(This is an extended blog post version of my talk “Ultraproducts as a Bridge Between Discrete and Continuous Analysis” that I gave at the Simons institute for the theory of computing at the workshop “Neo-Classical methods in discrete analysis“. Some of the material here is drawn from previous blog posts, notably “Ultraproducts as a bridge between hard analysis and soft analysis” and “Ultralimit analysis and quantitative algebraic geometry“‘. The text here has substantially more details than the talk; one may wish to skip all of the proofs given here to obtain a closer approximation to the original talk.)
Discrete analysis, of course, is primarily interested in the study of discrete (or “finitary”) mathematical objects: integers, rational numbers (which can be viewed as ratios of integers), finite sets, finite graphs, finite or discrete metric spaces, and so forth. However, many powerful tools in mathematics (e.g. ergodic theory, measure theory, topological group theory, algebraic geometry, spectral theory, etc.) work best when applied to continuous (or “infinitary”) mathematical objects: real or complex numbers, manifolds, algebraic varieties, continuous topological or metric spaces, etc. In order to apply results and ideas from continuous mathematics to discrete settings, there are basically two approaches. One is to directly discretise the arguments used in continuous mathematics, which often requires one to keep careful track of all the bounds on various quantities of interest, particularly with regard to various error terms arising from discretisation which would otherwise have been negligible in the continuous setting. The other is to construct continuous objects as limits of sequences of discrete objects of interest, so that results from continuous mathematics may be applied (often as a “black box”) to the continuous limit, which then can be used to deduce consequences for the original discrete objects which are quantitative (though often ineffectively so). The latter approach is the focus of this current talk.
The following table gives some examples of a discrete theory and its continuous counterpart, together with a limiting procedure that might be used to pass from the former to the latter:
| (Discrete) | (Continuous) | (Limit method) |
| Ramsey theory | Topological dynamics | Compactness |
| Density Ramsey theory | Ergodic theory | Furstenberg correspondence principle |
| Graph/hypergraph regularity | Measure theory | Graph limits |
| Polynomial regularity | Linear algebra | Ultralimits |
| Structural decompositions | Hilbert space geometry | Ultralimits |
| Fourier analysis | Spectral theory | Direct and inverse limits |
| Quantitative algebraic geometry | Algebraic geometry | Schemes |
| Discrete metric spaces | Continuous metric spaces | Gromov-Hausdorff limits |
| Approximate group theory | Topological group theory | Model theory |
As the above table illustrates, there are a variety of different ways to form a limiting continuous object. Roughly speaking, one can divide limits into three categories:
- Topological and metric limits. These notions of limits are commonly used by analysts. Here, one starts with a sequence (or perhaps a net) of objects
in a common space
, which one then endows with the structure of a topological space or a metric space, by defining a notion of distance between two points of the space, or a notion of open neighbourhoods or open sets in the space. Provided that the sequence or net is convergent, this produces a limit object
, which remains in the same space, and is “close” to many of the original objects
- Categorical limits. These notions of limits are commonly used by algebraists. Here, one starts with a sequence (or more generally, a diagram) of objects
or the inverse limit
of these objects, which is another object in the same category
- Logical limits. These notions of limits are commonly used by model theorists. Here, one starts with a sequence of objects
or of spaces
, each of which is (a component of) a model for given (first-order) mathematical language (e.g. if one is working in the language of groups,
or a new space
, which is still a model of the same language (e.g. if the spaces
.)
The purpose of this talk is to highlight the third type of limit, and specifically the ultraproduct construction, as being a “universal” limiting procedure that can be used to replace most of the limits previously mentioned. Unlike the topological or metric limits, one does not need the original objects
With so few requirements on the objects
Ultraproducts are not the only logical limit in the model theorist’s toolbox, but they are one of the simplest to set up and use, and already suffice for many of the applications of logical limits outside of model theory. In this post, I will set out the basic theory of these ultraproducts, and illustrate how they can be used to pass between discrete and continuous theories in each of the examples listed in the above table.
Apart from the initial “one-time cost” of setting up the ultraproduct machinery, the main loss one incurs when using ultraproduct methods is that it becomes very difficult to extract explicit quantitative bounds from results that are proven by transferring qualitative continuous results to the discrete setting via ultraproducts. However, in many cases (particularly those involving regularity-type lemmas) the bounds are already of tower-exponential type or worse, and there is arguably not much to be lost by abandoning the explicit quantitative bounds altogether.
Perhaps the most important structural result about general large dense graphs is the Szemerédi regularity lemma. Here is a standard formulation of that lemma:
Lemma 1 (Szemerédi regularity lemma) Let
be a graph on
vertices, and let
. Then there exists a partition
for some
with the property that for all but at most
of the pairs
, the pair
is
-regular in the sense that
whenever
are such that
and
, and
is the edge density between
. Furthermore, the partition is equitable in the sense that
for all

There are many proofs of this lemma, which is actually not that difficult to establish; see for instance these previous blog posts for some examples. In this post I would like to record one further proof, based on the spectral decomposition of the adjacency matrix of 
For reasons of exposition, it is convenient to first establish a slightly weaker form of the lemma, in which one drops the hypothesis of equitability (but then has to weight the cells 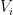
Lemma 2 (Szemerédi regularity lemma, weakened variant) . Let
outside of an exceptional set
, one has
whenever
, where
is the number of edges between
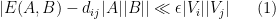

Let us now prove Lemma 2. We enumerate 




for some orthonormal basis 
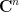

We can compute the trace of 

 , so
, so 
Among other things, this implies that

for all 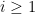
Let 
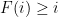

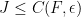
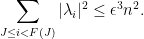
(Indeed, the bound on 



where 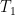
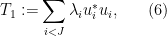
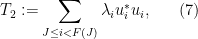
and 
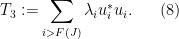
We now design a vertex partition to make 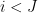




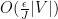

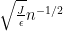
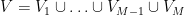

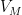
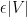



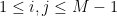
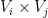

for any 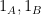
Next, we observe from (3) and (7) that 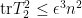
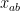
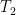
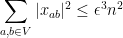
and hence by Markov’s inequality we have

for all pairs 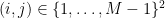
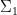
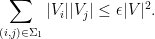

for any
Finally, to control 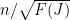
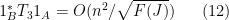
for any 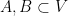
Let 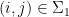
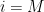

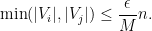
One easily verifies that (2) holds. If

for all 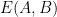
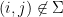
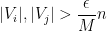
and so (since
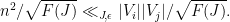
If we let
To prove Lemma 1, one argues similarly (after modifying 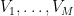
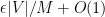
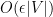
Remark 1 It is easy to verify that
in the partition. It was shown by Gowers that a tower-exponential bound is actually necessary here. By varying
essentially gives the weak regularity lemma of Frieze and Kannan.
Remark 2 If we specialise to a Cayley graph, in which
is a finite abelian group and
for some (symmetric) subset
of
Remark 3 The use of spectral theory here is parallel to the use of Fourier analysis to establish results such as Roth’s theorem on arithmetic progressions of length three. In analogy with this, one could view hypergraph regularity as being a sort of “higher order spectral theory”, although this spectral perspective is not as convenient as it is in the graph case.
I’ve just uploaded to the arXiv my paper “Expanding polynomials over finite fields of large characteristic, and a regularity lemma for definable sets“, submitted to Contrib. Disc. Math. The motivation of this paper is to understand a certain polynomial variant of the sum-product phenomenon in finite fields. This phenomenon asserts that if 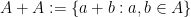




for some absolute constants 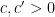
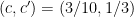


We have focused here on the case when
Note that it is necessary to have both 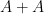
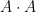
Now we consider a polynomial variant of the sum-product phenomenon, where we consider a polynomial image
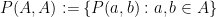
of a set 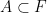
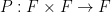

of two subsets 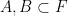





In this paper of Vu, it was shown that one could replace 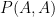
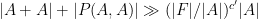
whenever 
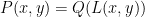
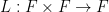
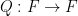
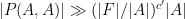
whenever
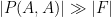
whenever

whenever 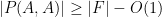
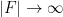
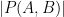
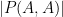
The example of a long arithmetic or geometric progression shows that the polynomials 

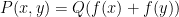


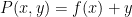
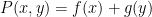
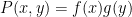
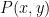
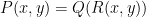





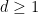

Our first main result improves upon the Bukh-Tsimerman result by strengthening the notion of expansion and removing the non-composite and monic hypotheses, but imposes a condition of large characteristic. I’ll state the result here slightly informally as follows:
Theorem 1 (Criterion for moderate expansion) Let
or
for some polynomials
. Then one has the (asymmetric) moderate expansion property
whenever
.

This is basically a sharp necessary and sufficient condition for asymmetric expansion moderate for polynomials of two variables. In the paper, analogous sufficient conditions for weak or almost strong expansion are also given, although these are not quite as satisfactory (particularly the conditions for almost strong expansion, which include a somewhat complicated algebraic condition which is not easy to check, and which I would like to simplify further, but was unable to).
The argument here resembles the Bukh-Tsimerman argument in many ways. One can view the result as an assertion about the expansion properties of the graph 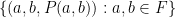

(actually, one should view this as a multiset, but let us ignore this technicality) which one expects to be a dense set in 

fails to be Zariski dense, but it turns out that in this case one can use some differential geometry and Riemann surface arguments (after first invoking the Lefschetz principle and the high characteristic hypothesis to work over the complex numbers instead over a finite field) to show that 

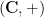
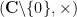
It remains to understand the structure of the set (2) is. To understand dense graphs or hypergraphs, one of the standard tools of choice is the Szemerédi regularity lemma, which carves up such graphs into a bounded number of cells, with the graph behaving pseudorandomly on most pairs of cells. However, the bounds in this lemma are notoriously poor (the regularity obtained is an inverse tower exponential function of the number of cells), and this makes this lemma unsuitable for the type of expansion properties we seek (in which we want to deal with sets 
Lemma 2 (Algebraic regularity lemma) Let
be definable sets over
,
for some bounded
that can be described by some first-order predicate in the language of rings of bounded length and involving boundedly many constants). Let
be a definable subset of
, again of bounded complexity (one can view
). Then one can partition
,
, still definable with bounded complexity, such that for all pairs
,
, one has the regularity property
for all
, where
is the density of
.

This lemma resembles the Szemerédi regularity lemma, but regularises all pairs of cells (not just most pairs), and the regularity is of polynomial strength in 
The above lemma is stated for graphs 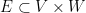
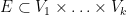



One feature of the proof of Lemma 2 which I found striking was the need to use some fairly high powered technology from algebraic geometry, and in particular the Lang-Weil bound on counting points in varieties over a finite field (discussed in this previous blog post), and also the theory of the etale fundamental group. Let me try to briefly explain why this is the case. A model example of a definable set of bounded complexity 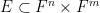

for some polynomial 

If one can show that this function 


One can recognise 
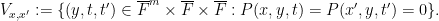
The Lang-Weil bound (discussed in this previous post) provides a formula for this count, in terms of the number 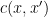
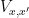
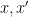
Here is where the étale fundamental group comes in. One can view 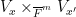
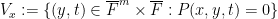
and
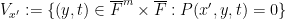
over 
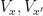
In order to expedite the deployment of all this algebraic geometry (as well as some Riemann surface theory), it is convenient to use the formalism of nonstandard analysis (or the ultraproduct construction), which among other things can convert quantitative, finitary problems in large characteristic into equivalent qualitative, infinitary problems in zero characteristic (in the spirit of this blog post). This allows one to use several tools from those fields as “black boxes”; not just the theory of étale fundamental groups (which are considerably simpler and more favorable in characteristic zero than they are in positive characteristic), but also some results limiting the morphisms between compact Riemann surfaces of high genus (such as the de Franchis theorem, the Riemann-Hurwitz formula, or the fact that all morphisms between elliptic curves are essentially group homomorphisms), which would be quite unwieldy to utilise if one did not first pass to the zero characteristic case (and thence to the complex case) via the ultraproduct construction (followed by the Lefschetz principle).
I found this project to be particularly educational for me, as it forced me to wander outside of my usual range by quite a bit in order to pick up the tools from algebraic geometry and Riemann surfaces that I needed (in particular, I read through several chapters of EGA and SGA for the first time). This did however put me in the slightly unnerving position of having to use results (such as the Riemann existence theorem) whose proofs I have not fully verified for myself, but which are easy to find in the literature, and widely accepted in the field. I suppose this type of dependence on results in the literature is more common in the more structured fields of mathematics than it is in analysis, which by its nature has fewer reusable black boxes, and so key tools often need to be rederived and modified for each new application. (This distinction is discussed further in this article of Gowers.)
Ben Green, and I have just uploaded to the arXiv our paper “An arithmetic regularity lemma, an associated counting lemma, and applications“, submitted (a little behind schedule) to the 70th birthday conference proceedings for Endre Szemerédi. In this paper we describe the general-degree version of the arithmetic regularity lemma, which can be viewed as the counterpart of the Szemerédi regularity lemma, in which the object being regularised is a function ![{f: [N] \rightarrow [0,1]}](https://s0.wp.com/latex.php?latex=%7Bf%3A+%5BN%5D+%5Crightarrow+%5B0%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![{[N] = \{1,\ldots,N\}}](https://s0.wp.com/latex.php?latex=%7B%5BN%5D+%3D+%5C%7B1%2C%5Cldots%2CN%5C%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

![{U^{s+1}[N]}](https://s0.wp.com/latex.php?latex=%7BU%5E%7Bs%2B1%7D%5BN%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
The regularity lemma is a manifestation of the “dichotomy between structure and randomness”, as discussed for instance in my ICM article or FOCS article. In the degree 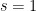
The regularity and counting lemmas are designed to be used together, and in the paper we give three applications of this combination. Firstly, we give a new proof of Szemerédi’s theorem, which proceeds via an energy increment argument rather than a density increment one. Secondly, we establish a conjecture of Bergelson, Host, and Kra, namely that if ![{A \subset [N]}](https://s0.wp.com/latex.php?latex=%7BA+%5Csubset+%5BN%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)




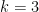
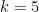
![{[N]}](https://s0.wp.com/latex.php?latex=%7B%5BN%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
In all three applications, the scheme of proof can be described as follows:
- Apply the arithmetic regularity lemma, and decompose a relevant function
.
- The uniform part
is so tiny in the Gowers uniformity norm that its contribution can be easily dealt with by an appropriate “generalised von Neumann theorem”.
- The contribution of the (virtual, irrational) nilsequence
can be controlled using the arithmetic counting lemma.
- Finally, one needs to check that the contribution of the small error
does not overwhelm the main term
To illustrate the last point, let us give the following example. Suppose we have a set 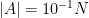
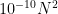
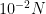

Unfortunately, the answer could be no; conceivably, all of the 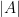

But suppose we knew that the 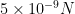
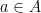
A succinct (but slightly inaccurate) summation of the regularity+counting lemma strategy would be that in order to solve a problem in additive combinatorics, it “suffices to check it for nilsequences”. But this should come with a caveat, due to the issue of the small error above; in addition to checking it for nilsequences, the answer in the nilsequence case must be sufficiently “dispersed” in a suitable sense, so that it can survive the addition of a small (but not completely negligible) perturbation.
One last “production note”. Like our previous paper with Emmanuel Breuillard, we used Subversion to write this paper, which turned out to be a significant efficiency boost as we could work on different parts of the paper simultaneously (this was particularly important this time round as the paper was somewhat lengthy and complicated, and there was a submission deadline). When doing so, we found it convenient to split the paper into a dozen or so pieces (one for each section of the paper, basically) in order to avoid conflicts, and to help coordinate the writing process. I’m also looking into git (a more advanced version control system), and am planning to use it for another of my joint projects; I hope to be able to comment on the relative strengths of these systems (and with plain old email) in the future.
This week I am at Rutgers University, giving the Lewis Memorial Lectures for this year, which are also concurrently part of a workshop in random matrices. I gave four lectures, three of which were on random matrices, and one of which was on the Szemerédi regularity lemma.
The titles, abstracts, and slides of these talks are as follows.
- Szemerédi’s lemma revisited. In this general-audience talk, I discuss the Szemerédi regularity lemma (which, roughly speaking, shows that an arbitrary large dense graph can always be viewed as the disjoint union of a bounded number of pseudorandom components), and how it has recently been reinterpreted in a more analytical (and infinitary) language using the theory of graph limits or of exchangeable measures. I also discuss arithmetic analogues of this lemma, including one which (implicitly) underlies my result with Ben Green that the primes contain arbitrarily long arithmetic progressions.
- Singularity and determinant of random matrices. Here, I present recent progress in understanding the question of how likely a random matrix (e.g. one whose entries are all +1 or -1 with equal probability) is to be invertible, as well as the related question of how large the determinant should be. The case of continuous matrix ensembles (such as the Gaussian ensemble) is well understood, but the discrete case contains some combinatorial difficulties and took longer to understand properly. In particular I present the results of Kahn-Komlós-Szemerédi and later authors showing that discrete random matrices are invertible with exponentially high probability, and also give some results for the distribution of the determinant.
- The least singular value of random matrices. A more quantitative version of the question “when is a matrix invertible?” is “what is the least singular value of that matrix”? I present here the recent results of Litvak-Pajor-Rudelson-Tomczak-Jaegermann, Rudelson, myself and Vu, and Rudelson–Vershynin on addressing this question in the discrete case. A central role is played by the inverse Littlewood-Offord theorems of additive combinatorics, which give reasonably sharp necessary conditions for a discrete random walk to concentrate in a small ball.
- The circular law. One interesting application of the above theory is to extend the circular law for the spectrum of random matrices from the continuous case to the discrete case. Previous arguments of Girko and Bai for the continuous case can be transplanted to the discrete case, but the key new ingredient needed is a least singular value bound for shifted matrices
in order to avoid the spectrum being overwhelmed by pseudospectrum. It turns out that the results of the preceding lecture are almost precisely what are needed to accomplish this.
[Update, Mar 31: first lecture slides corrected. Thanks to Yoshiyasu Ishigami for pointing out a slight inaccuracy in the text.]
I’ve just uploaded to the arXiv my joint paper with Tim Austin, “On the testability and repair of hereditary hypergraph properties“, which has been submitted to Random Structures and Algorithms. In this paper we prove some positive and negative results for the testability (and the local repairability) of various properties of directed or undirected graphs and hypergraphs, which can be either monochromatic or multicoloured.
The negative results have already been discussed in a previous posting of mine, so today I will focus on the positive results. The property testing results here are finitary results, but it turns out to be rather convenient to use a certain correspondence principle (the hypergraph version of the Furstenberg correspondence principle) to convert the question into one about exchangeable probability measures on spaces of hypergraphs (i.e. on random hypergraphs whose probability distribution is invariant under exchange of vertices). Such objects are also closely related to the”graphons” and “hypergraphons” that emerge as graph limits, as studied by Lovasz-Szegedy, Elek-Szegedy, and others. Somewhat amusingly, once one does so, it then becomes convenient to keep track of objects indexed by vertex sets and how they are exchanged via the language of category theory, and in particular using the concept of a natural transformation to describe such objects as exchangeable measures, graph colourings, and local modification rules. I will try to sketch out some of these connections, after describing the main positive results.
This post is a sequel of sorts to my earlier post on hard and soft analysis, and the finite convergence principle. Here, I want to discuss a well-known theorem in infinitary soft analysis – the Lebesgue differentiation theorem – and whether there is any meaningful finitary version of this result. Along the way, it turns out that we will uncover a simple analogue of the Szemerédi regularity lemma, for subsets of the interval rather than for graphs. (Actually, regularity lemmas seem to appear in just about any context in which fine-scaled objects can be approximated by coarse-scaled ones.) The connection between regularity lemmas and results such as the Lebesgue differentiation theorem was recently highlighted by Elek and Szegedy, while the connection between the finite convergence principle and results such as the pointwise ergodic theorem (which is a close cousin of the Lebesgue differentiation theorem) was recently detailed by Avigad, Gerhardy, and Towsner.
The Lebesgue differentiation theorem has many formulations, but we will avoid the strongest versions and just stick to the following model case for simplicity:
Lebesgue differentiation theorem. If
is Lebesgue measurable, then for almost every
we have
. Equivalently, the fundamental theorem of calculus
is true for almost every x in [0,1].
Here we use the oriented definite integral, thus 
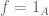
Lebesgue density theorem. Let
be Lebesgue measurable. Then for almost every
, we have
as
, where |A| denotes the Lebesgue measure of A.
In other words, almost all the points x of A are points of density of A, which roughly speaking means that as one passes to finer and finer scales, the immediate vicinity of x becomes increasingly saturated with A. (Points of density are like robust versions of interior points, thus the Lebesgue density theorem is an assertion that measurable sets are almost like open sets. This is Littlewood’s first principle.) One can also deduce the Lebesgue differentiation theorem back from the Lebesgue density theorem by approximating f by a finite linear combination of indicator functions; we leave this as an exercise.
In this second lecture, I wish to talk about the dichotomy between structure and randomness as it manifests itself in four closely related areas of mathematics:
- Combinatorial number theory, which seeks to find patterns in unstructured dense sets (or colourings) of integers;
- Ergodic theory (or more specifically, multiple recurrence theory), which seeks to find patterns in positive-measure sets under the action of a discrete dynamical system on probability spaces (or more specifically, measure-preserving actions of the integers
);
- Graph theory, or more specifically the portion of this theory concerned with finding patterns in large unstructured dense graphs; and
- Ergodic graph theory, which is a very new and undeveloped subject, which roughly speaking seems to be concerned with the patterns within a measure-preserving action of the infinite permutation group
, which is one of several models we have available to study infinite “limits” of graphs.
The two “discrete” (or “finitary”, or “quantitative”) fields of combinatorial number theory and graph theory happen to be related to each other, basically by using the Cayley graph construction; I will give an example of this shortly. The two “continuous” (or “infinitary”, or “qualitative”) fields of ergodic theory and ergodic graph theory are at present only related on the level of analogy and informal intuition, but hopefully some more systematic connections between them will appear soon.
On the other hand, we have some very rigorous connections between combinatorial number theory and ergodic theory, and also (more recently) between graph theory and ergodic graph theory, basically by the procedure of viewing the infinitary continuous setting as a limit of the finitary discrete setting. These two connections go by the names of the Furstenberg correspondence principle and the graph correspondence principle respectively. These principles allow one to tap the power of the infinitary world (for instance, the ability to take limits and perform completions or closures of objects) in order to establish results in the finitary world, or at least to take the intuition gained in the infinitary world and transfer it to a finitary setting. Conversely, the finitary world provides an excellent model setting to refine one’s understanding of infinitary objects, for instance by establishing quantitative analogues of “soft” results obtained in an infinitary manner. I will remark here that this best-of-both-worlds approach, borrowing from both the finitary and infinitary traditions of mathematics, was absolutely necessary for Ben Green and I in order to establish our result on long arithmetic progressions in the primes. In particular, the infinitary setting is excellent for being able to rigorously define and study concepts (such as structure or randomness) which are much “fuzzier” and harder to pin down exactly in the finitary world.

Recent Comments