
You are currently browsing the category archive for the ‘math.IT’ category.
A family 
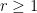
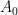
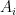
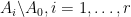

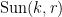


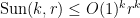


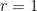
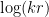
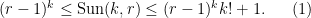

Rao’s argument used the Shannon noiseless coding theorem. It turns out that the argument can be arranged in the very slightly different language of Shannon entropy, and I would like to present it here. The argument proceeds by locating the core and petals of the sunflower separately (this strategy is also followed in Alweiss-Lovett-Wu-Zhang). In both cases the following definition will be key. In this post all random variables, such as random sets, will be understood to be discrete random variables taking values in a finite range. We always use boldface symbols to denote random variables, and non-boldface for deterministic quantities.
Definition 1 (Spread set) Let. A random set
is said to be
-spread if one has
for all sets
. A family
of sets is said to be
is non-empty and the random variable
is
is drawn uniformly from

The core can then be selected greedily in such a way that the remainder of a family becomes spread:
Lemma 2 (Locating the core) Let, each of cardinality at most
of cardinality at most
has cardinality at least
, and such that the family
is
and the
.
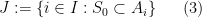
Proof: We may assume 
 be a subset of that maximizes
be a subset of that maximizes  . Since
. Since  and
and  when
when 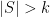 , we see that
, we see that 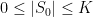 . If the are distinct and , then we also have
. If the are distinct and , then we also have 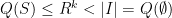 when
when 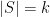 , thus in this case we have .
, thus in this case we have .
Let 


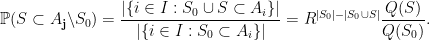
 , and the probability is only non-empty when
, and the probability is only non-empty when 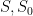 are disjoint, so that
are disjoint, so that  . The claim follows.
. The claim follows. 
In view of the above lemma, the bound (2) will then follow from
Proposition 3 (Locating the petals) Letbe natural numbers, and suppose that
for a sufficiently large constant
. Let
such that
is disjoint.
Indeed, to prove (2), we assume that 






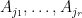
Remark 4 Proposition 3 is easy to prove if we strengthen the condition on. In this case, we have
for every
, hence by the union bound we see that for any
with
there exists
such that
is disjoint from the set
, which has cardinality at most
. Iterating this, we obtain the conclusion of Proposition 3 in this case. This recovers a bound of the form
, and by pursuing this idea a little further one can recover the original upper bound (1) of Erdös and Rado.
It remains to prove Proposition 3. In fact we can locate the petals one at a time, placing each petal inside a random set.
Proposition 5 (Locating a single petal) Let the notation and hypotheses be as in Proposition 3. Letbe a random subset of
. Then with probability greater than
,
To see that Proposition 5 implies Proposition 3, we randomly partition 

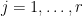
We will prove Proposition 5 by gradually increasing the density of the random set and arranging the sets
Proposition 6 (Refinement inequality) Let. Let
. Then there exists another
of
and

Note that a direct application of the first moment method gives only the bound
 to an equivalent we can replace the
to an equivalent we can replace the  factor by a quantity significantly smaller than
factor by a quantity significantly smaller than  .
.
One can iterate the above proposition, repeatedly replacing 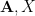
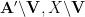
Corollary 7 (Iterated refinement inequality) Let. Let
. Then there exists another random subset

Now we can prove Proposition 5. Let 

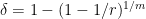

 , so that
, so that  , then by choice of we have
, then by choice of we have  , hence
, hence 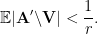
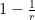 , there must exist such that
, there must exist such that  , giving the proposition.
, giving the proposition.
It remains to establish Proposition 6. This is the difficult step, and requires a clever way to find the variant 


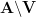
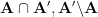



In these notes we presume familiarity with the basic concepts of probability theory, such as random variables (which could take values in the reals, vectors, or other measurable spaces), probability, and expectation. Much of this theory is in turn based on measure theory, which we will also presume familiarity with. See for instance this previous set of lecture notes for a brief review.
The basic objects of study in analytic number theory are deterministic; there is nothing inherently random about the set of prime numbers, for instance. Despite this, one can still interpret many of the averages encountered in analytic number theory in probabilistic terms, by introducing random variables into the subject. Consider for instance the form

of the prime number theorem (where we take the limit 

where 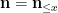

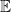
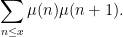
After dividing by

With probabilistic intuition, one may expect the random variables 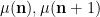
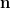


which by (2) is equal to 
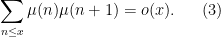
The asymptotic (3) is widely believed (it is a special case of the Chowla conjecture, which we will discuss in later notes; while there has been recent progress towards establishing it rigorously, it remains open for now.
How would one try to make these probabilistic intuitions more rigorous? The first thing one needs to do is find a more quantitative measurement of what it means for two random variables to be “approximately” independent. There are several candidates for such measurements, but we will focus in these notes on two particularly convenient measures of approximate independence: the “
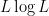

of (3), which is implied by (3) but strictly weaker (much as the prime number theorem (1) implies the bound 
As with many other situations in analytic number theory, we can exploit the fact that certain assertions (such as approximate independence) can become significantly easier to prove if one only seeks to establish them on average, rather than uniformly. For instance, given two random variables 



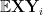


Just a short post to note that Norwegian Academy of Science and Letters has just announced that the 2017 Abel prize has been awarded to Yves Meyer, “for his pivotal role in the development of the mathematical theory of wavelets”. The actual prize ceremony will be at Oslo in May.
I am actually in Oslo myself currently, having just presented Meyer’s work at the announcement ceremony (and also having written a brief description of some of his work). The Abel prize has a somewhat unintuitive (and occasionally misunderstood) arrangement in which the presenter of the work of the prize is selected independently of the winner of the prize (I think in part so that the choice of presenter gives no clues as to the identity of the laureate). In particular, like other presenters before me (which in recent years have included Timothy Gowers, Jordan Ellenberg, and Alex Bellos), I agreed to present the laureate’s work before knowing who the laureate was! But in this case the task was very easy, because Meyer’s areas of (both pure and applied) harmonic analysis and PDE fell rather squarely within my own area of expertise. (I had previously written about some other work of Meyer in this blog post.) Indeed I had learned about Meyer’s wavelet constructions as a graduate student while taking a course from Ingrid Daubechies. Daubechies also made extremely important contributions to the theory of wavelets, but due to a conflict of interest (as per the guidelines for the prize committee) arising from Daubechies’ presidency of the International Mathematical Union (which nominates the majority of the members of the Abel prize committee, who then serve for two years) from 2011 to 2014 (and her continuing service ex officio on the IMU executive committee from 2015 to 2018), she will not be eligible for the prize until 2021 at the earliest, and so I do not think this prize should be necessarily construed as a judgement on the relative contributions of Meyer and Daubechies to this field. (In any case I fully agree with the Abel prize committee’s citation of Meyer’s pivotal role in the development of the theory of wavelets.)
[Update, Mar 28: link to prize committee guidelines and clarification of the extent of Daubechies’ conflict of interest added. -T]
Given a random variable
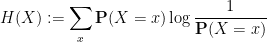
with the convention that 


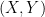
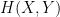

so we can define some further nonnegative quantities, the mutual information

and the conditional entropies

More generally, given three random variables 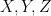

and the final of the Shannon entropy inequalities asserts that this quantity is also non-negative.
The mutual information 

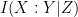





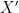
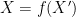


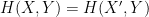
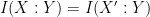

One can get some initial intuition for these information-theoretic quantities by specialising to a simple situation in which all the random variables 


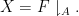
In this case, 
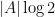
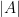


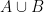

| Random variables |
Finite sets  |
Entropy 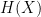 |
Cardinality |
| Joint variable |
Union |
| Mutual information |
Intersection cardinality 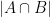 |
| Conditional entropy |
Set difference cardinality 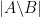 |
| Conditional mutual information |
 |
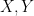 independent independent |
 disjoint disjoint |
| determined by |
a subset of |
| conditionally independent relative to |
 |
Every (linear) inequality or identity about entropy (and related quantities, such as mutual information) then specialises to a combinatorial inequality or identity about finite sets that is easily verified. For instance, the Shannon inequality 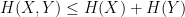
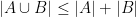
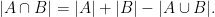
For a more advanced example, consider the data processing inequality that asserts that if 
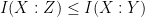

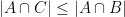

and a further inspection of the diagram then reveals the more precise identity

Using the dictionary in the reverse direction, one is then led to conjecture the identity
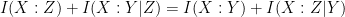
which (together with non-negativity of conditional mutual information) implies the data processing inequality, and this identity is in turn easily established from the definition of mutual information.
On the other hand, not every assertion about cardinalities of sets generalises to entropies of random variables that are not arising from restricting random boolean functions to sets. For instance, a basic property of sets is that disjointness from a given set
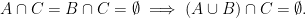
Indeed, one has the union bound

Applying the dictionary in the reverse direction, one might now conjecture that if
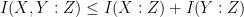
but these statements are well known to be false (for reasons related to pairwise independence of random variables being strictly weaker than joint independence). For a concrete counterexample, one can take 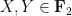
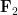

From the inclusion-exclusion identities



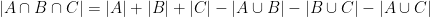

one can check that (1) is equivalent to the trivial lower bound 


However, this issue only arises with three or more variables; it is not too difficult to show that the only linear equalities and inequalities that are necessarily obeyed by the information-theoretic quantities 

One can work with a larger class of special cases of Shannon entropy by working with random linear functions rather than random boolean functions. Namely, let 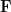



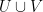
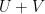





| Random variables |
Subspaces 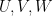 |
| Entropy |
Dimension 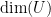 |
| Joint variable |
Sum |
| Mutual information |
Dimension of intersection  |
| Conditional entropy |
Dimension of projection  |
| Conditional mutual information |
 |
| independent |
transverse ( ) ) |
| determined by |
a subspace of  |
| conditionally independent relative to |
 , ,  transverse. transverse. |
The combinatorial dictionary can be regarded as a specialisation of the linear algebra dictionary, by taking 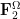


As before, every linear inequality or equality that is valid for the information-theoretic quantities discussed above, is automatically valid for the linear algebra counterparts for subspaces of a vector space over a finite field by applying the above specialisation (and dividing out by the normalising factor of
The linear algebra model captures more of the features of Shannon entropy than the combinatorial model. For instance, in contrast to the combinatorial case, it is possible in the linear algebra setting to have subspaces 



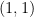

However, the linear algebra model does not completely capture the subtleties of Shannon entropy once one works with four or more variables (or subspaces). This was first observed by Ingleton, who established the dimensional inequality

for any subspaces 



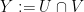
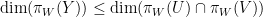
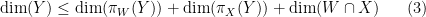
which can be rearranged using 


but this is clear since 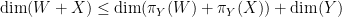
Returning to the entropy setting, the analogue

of (3) is true (exercise!), but the analogue

of Ingleton’s inequality is false in general. Again, this is easiest to see when all the terms on the right-hand side vanish; then 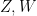

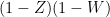
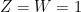

I do not know if there is any simpler model of Shannon entropy that captures all the inequalities available for four variables. One significant complication is that there exist some information inequalities in this setting that are not of Shannon type, such as the Zhang-Yeung inequality

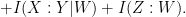
One can however still use these simpler models of Shannon entropy to be able to guess arguments that would work for general random variables. An example of this comes from my paper on the logarithmically averaged Chowla conjecture, in which I showed among other things that
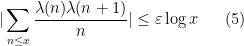
whenever 


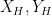

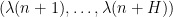

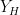




on the mutual information between
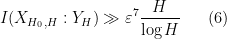
for any 



and from concatenating sign patterns one could see that 




![{[H_-,H_+]}](https://s0.wp.com/latex.php?latex=%7B%5BH_-%2CH_%2B%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
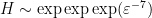
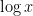

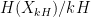

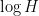


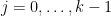

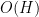

for various sets 


However, on considering the set model recently, I realised that one can be a little more efficient by exploiting the fact (basically the Chinese remainder theorem) that the random variables

of (6), which in the set model roughly speaking asserts that each 

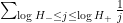
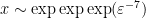

for a small constant 


Let 

In particular, if it is rare for
If 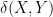

for any 
A basic inequality in information theory is Pinsker’s inequality

where the Kullback-Leibler divergence 

(See this previous blog post for a proof of this inequality.) A standard application of Jensen’s inequality reveals that 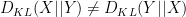

Thus, if
We can specialise this inequality to the case when 
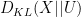
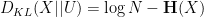
where
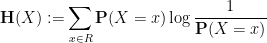
is the Shannon entropy of 

Thus, if 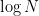
The inequality (2) is only useful when the entropy 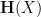



Lemma 1 (Pinsker-type inequality) Let

Proof: Consider the conditional entropy 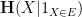



by Jensen’s inequality. On the other hand, one has

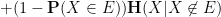


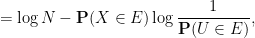
where we have again used Jensen’s inequality. Putting the two inequalities together, we obtain the claim.
Remark 2 As noted in comments, this inequality can be viewed as a special case of the more general inequality
for arbitrary random variables
for arbitrary functions
. Indeed one has
where
is the entropy function.


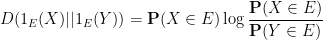

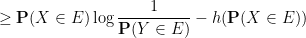

Thus, for instance, if one has

and

for some 


More informally: if the entropy of 
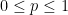
It turns out that the above lemma combines well with concentration of measure estimates; in my paper, I used one of the simplest such estimates, namely Hoeffding’s inequality, but there are of course many other estimates of this type (see e.g. this previous blog post for some others). Roughly speaking, concentration of measure inequalities allow one to make approximations such as

with exponentially high probability, where

with somewhat high probability, if the entropy of


for “most” choices of 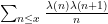

A handy inequality in additive combinatorics is the Plünnecke-Ruzsa inequality:
Theorem 1 (Plünnecke-Ruzsa inequality) Let
be finite non-empty subsets of an additive group
, such that
for all
and some scalars
. Then there exists a subset
of
.
The proof uses graph-theoretic techniques. Setting 
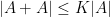
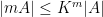
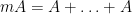
In a recent paper, I adapted a number of sum set estimates to the entropy setting, in which finite sets such as 
I recently discovered, however, that buried in a classic paper of Kaimonovich and Vershik (implicitly in Proposition 1.3, to be precise) there was the following analogue of Theorem 1:
Theorem 2 (Entropy Plünnecke-Ruzsa inequality) Let
be independent random variables of finite entropy taking values in an additive group
for all
.
In fact Theorem 2 is a bit “better” than Theorem 1 in the sense that Theorem 1 needed to refine the original set 
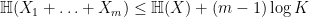
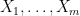
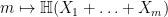
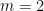

Theorem 2 is actually a quick consequence of the submodularity inequality

in information theory, which is valid whenever 
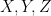


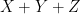

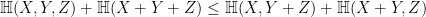
which after using the independence of

(this inequality was also recently observed by Madiman; it is the

and Theorem 2 follows by telescoping series.
The proof of Theorem 2 seems to be genuinely different from the graph-theoretic proof of Theorem 1. It would be interesting to see if the above argument can be somehow adapted to give a stronger version of Theorem 1. Note also that both Theorem 1 and Theorem 2 have extensions to more general combinations of 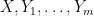
I am posting here four more of my Mahler lectures, each of which is based on earlier talks of mine:
- Compressed sensing. This is an updated and reformatted version of my ANZIAM talk on this topic.
- Discrete random matrices. This talk is a survey on recent developments on the universality phenomenon in random matrices, including work of myself and Van Vu. It covers similar material to my Netanyahu lecture, which has not previously appeared in electronic form.
- Recent progress in additive prime number theory. This is an updated and reformatted version of my AMS lecture on this topic.
- Recent progress on the Kakeya conjecture. This is an updated and reformatted version of my Fefferman conference lecture.
As always, comments, corrections, and other feedback are welcome.
There are many situations in combinatorics in which one is running some sort of iteration algorithm to continually “improve” some object
A basic strategy to ensure termination of an algorithm is to exploit a monotonicity property, or more precisely to show that some key quantity keeps increasing (or keeps decreasing) with each loop of the algorithm, while simultaneously staying bounded. (Or, as the economist Herbert Stein was fond of saying, “If something cannot go on forever, it must stop.”)
Here are four common flavours of this monotonicity strategy:
- The mass increment argument. This is perhaps the most familiar way to ensure termination: make each improved object
). Dually, one can try to force the amount of “mass” remaining “outside” of
sense), and this should force some desirable property on
- The density increment argument. This is a variant of the mass increment argument, in which one increments the “density” of
, and one seeks to improve
) in such a way that the density of the new object in the new ambient space is better than that of the previous object (e.g.
for some
- The energy increment argument. This is an “
“-based density increment argument), in which one seeks to increments the amount of “energy” that
- The rank reduction argument. Here, one seeks to make each new object
Much of my own work in additive combinatorics relies heavily on at least one of these types of arguments (and, in some cases, on a nested combination of two or more of them). Many arguments in nonlinear partial differential equations also have a similar flavour, relying on various monotonicity formulae for solutions to such equations, though the objective in PDE is usually slightly different, in that one wants to keep control of a solution as one approaches a singularity (or as some time or space coordinate goes off to infinity), rather than to ensure termination of an algorithm. (On the other hand, many arguments in the theory of concentration compactness, which is used heavily in PDE, does have the same algorithm-terminating flavour as the combinatorial arguments; see this earlier blog post for more discussion.)
Recently, a new species of monotonicity argument was introduced by Moser, as the primary tool in his elegant new proof of the Lovász local lemma. This argument could be dubbed an entropy compression argument, and only applies to probabilistic algorithms which require a certain collection 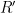
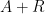
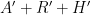
It is interesting to compare this method with the ones discussed earlier. In the previous methods, the failure of the algorithm to halt led to a new iteration of the object
Below the fold I give a special case of Moser’s argument, based on a blog post of Lance Fortnow on this topic.
The most fundamental unsolved problem in complexity theory is undoubtedly the P=NP problem, which asks (roughly speaking) whether a problem which can be solved by a non-deterministic polynomial-time (NP) algorithm, can also be solved by a deterministic polynomial-time (P) algorithm. The general belief is that 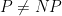
One reason why the 

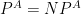
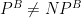
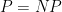
The Baker-Gill-Solovay result was quite surprising, but the idea of the proof turns out to be rather simple. To get an oracle 
Unfortunately, the simple idea of the proof can be obscured by various technical details (e.g. using Turing machines to define 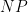
[This post should have appeared several months ago, but I didn’t have a link to the newsletter at the time, and I subsequently forgot about it until now. -T.]
Last year, Emmanuel Candés and I were two of the recipients of the 2008 IEEE Information Theory Society Paper Award, for our paper “Near-optimal signal recovery from random projections: universal encoding strategies?” published in IEEE Inf. Thy.. (The other recipient is David Donoho, for the closely related paper “Compressed sensing” in the same journal.) These papers helped initiate the modern subject of compressed sensing, which I have talked about earlier on this blog, although of course they also built upon a number of important precursor results in signal recovery, high-dimensional geometry, Fourier analysis, linear programming, and probability. As part of our response to this award, Emmanuel and I wrote a short piece commenting on these developments, entitled “Reflections on compressed sensing“, which appears in the Dec 2008 issue of the IEEE Information Theory newsletter. In it we place our results in the context of these precursor results, and also mention some of the many active directions (theoretical, numerical, and applied) that compressed sensing is now developing in.

Recent Comments