
You are currently browsing the category archive for the ‘275A – probability theory’ category.
In the previous set of notes we established the central limit theorem, which we formulate here as follows:
Theorem 1 (Central limit theorem) Let
be iid copies of a real random variable
of mean
and variance
, and write
. Then, for any fixed
, we have

This is however not the end of the matter; there are many variants, refinements, and generalisations of the central limit theorem, and the purpose of this set of notes is to present a small sample of these variants.
First of all, the above theorem does not quantify the rate of convergence in (1). We have already addressed this issue to some extent with the Berry-Esséen theorem, which roughly speaking gives a convergence rate of 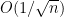

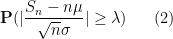
in the setting where 

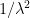
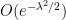
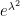
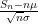
In the other direction, we can also look at the fine scale behaviour of the sums 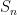

where 


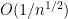
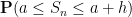


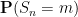
We also discuss other limit theorems in which the limiting distribution is something other than the normal distribution. Perhaps the most common example of these theorems is the Poisson limit theorems, in which one sums a large number of indicator variables (or approximate indicator variables), each of which is rarely non-zero, but which collectively add up to a random variable of medium-sized mean. In this case, it turns out that the limiting distribution should be a Poisson random variable; this again is an easy application of the Fourier method. Finally, we briefly discuss limit theorems for other stable laws than the normal distribution, which are suitable for summing random variables of infinite variance, such as the Cauchy distribution.
Finally, we mention a very important class of generalisations to the CLT (and to the variants of the CLT discussed in this post), in which the hypothesis of joint independence between the variables 
Let 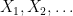
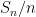

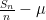


and

Then, as computed in previous notes, the normalised fluctuation 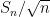


This and Chebyshev’s inequality already indicates that the “typical” size of 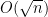

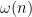

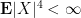

From this and the Paley-Zygmund inequality (Exercise 44 of Notes 1) we also get some lower bound for 
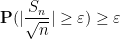
for some absolute constant 

The question remains as to what happens to the ratio
Proposition 1 Let
Proof: Suppose for contradiction that some sequence 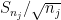


Nevertheless there is an important limit for the ratio
Definition 2 (Vague convergence and convergence in distribution) Let
be a locally compact Hausdorff topological space with the Borel
-algebra. A sequence of finite measures
on
as
. (Vague convergence is also known as weak convergence, although strictly speaking the terminology weak-* convergence would be more accurate.) A sequence of random variables
taking values in
converge vaguely to the distribution
, or equivalently if
as

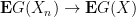
One could in principle try to extend this definition beyond the locally compact Hausdorff setting, but certain pathologies can occur when doing so (e.g. failure of the Riesz representation theorem), and we will never need to consider vague convergence in spaces that are not locally compact Hausdorff, so we restrict to this setting for simplicity.
Note that the notion of convergence in distribution depends only on the distribution of the random variables involved. One consequence of this is that convergence in distribution does not produce unique limits: if 

From the dominated convergence theorem (available for both convergence in probability and almost sure convergence) we see that convergence in probability or almost sure convergence implies convergence in distribution. The converse is not true, due to the insensitivity of convergence in distribution to equivalence in distribution; for instance, if
Remark 3 The notion of convergence in distribution is somewhat similar to the notion of convergence in the sense of distributions that arises in distribution theory (discussed for instance in this previous blog post), however strictly speaking the two notions of convergence are distinct and should not be confused with each other, despite the very similar names.
The notion of convergence in distribution simplifies in the case of real scalar random variables:
Proposition 4 Let
- (i)
- (ii)
converges to
for each continuity point
of
(i.e. for all real numbers
at which
is the cumulative distribution function of
Proof: First suppose that 


for every ![{t' \in [t-\delta,t+\delta]}](https://s0.wp.com/latex.php?latex=%7Bt%27+%5Cin+%5Bt-%5Cdelta%2Ct%2B%5Cdelta%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)




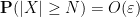
and
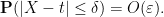
Let ![{G: {\bf R} \rightarrow [0,1]}](https://s0.wp.com/latex.php?latex=%7BG%3A+%7B%5Cbf+R%7D+%5Crightarrow+%5B0%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![{[-2N, t]}](https://s0.wp.com/latex.php?latex=%7B%5B-2N%2C+t%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![{[-N, t-\delta]}](https://s0.wp.com/latex.php?latex=%7B%5B-N%2C+t-%5Cdelta%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

and hence

for large enough
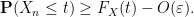
A similar argument, replacing 
![{[t,2N]}](https://s0.wp.com/latex.php?latex=%7B%5Bt%2C2N%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
![{[t+\delta,N]}](https://s0.wp.com/latex.php?latex=%7B%5Bt%2B%5Cdelta%2CN%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
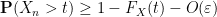
for

for 
Conversely, suppose that 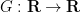
![{G_\varepsilon(t) = \sum_{i=1}^n c_i 1_{(t_i,t_{i+1}]}}](https://s0.wp.com/latex.php?latex=%7BG_%5Cvarepsilon%28t%29+%3D+%5Csum_%7Bi%3D1%7D%5En+c_i+1_%7B%28t_i%2Ct_%7Bi%2B1%7D%5D%7D%7D&bg=ffffff&fg=000000&s=0&c=20201002)


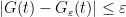
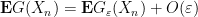
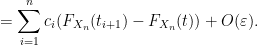
Similarly for

and on sending
The restriction to continuity points of 

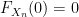

Example 5 For any natural number
, and let
. Then
Example 6 For any natural number
, then
Exercise 7 (Portmanteau theorem) Show that the properties (i) and (ii) in Proposition 4 are also equivalent to the following three statements:
- (iii) One has
for all closed sets
.
- (iv) One has
for all open sets
.
- (v) For any Borel set
whose topological boundary
is such that
, one has
.
(Note: to prove this theorem, you may wish to invoke Urysohn’s lemma. To deduce (iii) from (i), you may wish to start with the case of compact
.)
We can now state the famous central limit theorem:
Theorem 8 (Central limit theorem) Let
and finite non-zero variance
. Let
converges in distribution to a random variable with the standard normal distribution
(that is to say, a random variable with probability density function
). Thus, by abuse of notation
In the normalised case
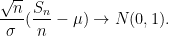

Using Proposition 4 (and the fact that the cumulative distribution function associated to

as

Informally, one can think of the central limit theorem as asserting that 


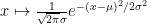
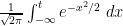


The central limit theorem is a basic example of the universality phenomenon in probability – many statistics involving a large system of many independent (or weakly dependent) variables (such as the normalised sums 
We will give several proofs of the central limit theorem in these notes; each of these proofs has their advantages and disadvantages, and can each extend to prove many further results beyond the central limit theorem. We first give Lindeberg’s proof of the central limit theorem, based on exchanging (or swapping) each component 
The following exercise illustrates the power of the central limit theorem, by establishing combinatorial estimates which would otherwise require the use of Stirling’s formula to establish.
Exercise 9 (De Moivre-Laplace theorem) Let
with
, thus
and variance
. Let
.
- (i) Show that
with
. (This is an example of a binomial distribution.)
- (ii) Assume Stirling’s formula
where
is a function of
as
.
The above special case of the central limit theorem was first established by de Moivre and Laplace.


We close this section with some basic facts about convergence of distribution that will be useful in the sequel.
Exercise 10 Let
be sequences of real random variables, and let
be further real random variables.
- (i) If
- (ii) Suppose that
for each
converges in distribution to
if and only if
- (iii) If
such that
for all sufficiently large
- (iv) Show that
and
of
converges almost surely to
- (v) If
is continuous, show that
converges in distribution to
. Generalise this claim to the case when
- (vi) (Slutsky’s theorem) If
converges in distribution to
, and
converges in distribution to
. (Hint: either use (iv), or else use (iii) to control some error terms.) This statement combines particularly well with (i). What happens if
- (vii) (Fatou lemma) If
is continuous, and
.
- (viii) (Bounded convergence) If
.
- (ix) (Dominated convergence) If
almost surely for all
.
For future reference we also mention (but will not prove) Prokhorov’s theorem that gives a partial converse to part (iii) of the above exercise:
Theorem 11 (Prokhorov’s theorem) Let
for all sufficiently large
which converges in distribution to some random variable
The proof of this theorem relies on the Riesz representation theorem, and is beyond the scope of this course; but see for instance Exercise 29 of this previous blog post. (See also the closely related Helly selection theorem, covered in Exercise 30 of the same post.)
One of the major activities in probability theory is studying the various statistics that can be produced from a complex system with many components. One of the simplest possible systems one can consider is a finite sequence 
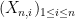

The first fundamental result about these sums is the law of large numbers (or LLN for short), which comes in two formulations, weak (WLLN) and strong (SLLN). To state these laws, we first must define the notion of convergence in probability.
Definition 1 Let
(e.g. the
or
), and let
as
are scalar, we have
as
The measure-theoretic analogue of convergence in probability is convergence in measure.
It is instructive to compare the notion of convergence in probability with almost sure convergence. it is easy to see that 


We have the following easy relationships between convergence in probability and almost sure convergence:
Exercise 2 Let
- (i) If
almost surely, show that
- (ii) Suppose that
for all
- (iii) If
almost surely.
- (iv) If
are absolutely integrable and
as
- (v) (Urysohn subsequence principle) Suppose that every subsequence
that converges to
- (vi) Does the Urysohn subsequence principle still hold if “in probability” is replaced with “almost surely” throughout?
- (vii) If
is continuous, show that
converges in probability to
,
is a sequence of scalar random variables that converge in probability to
, and
or
is continuous, show that
converges in probability to
. (Thus, for instance, if
and
- (viii) (Fatou’s lemma for convergence in probability) If
.
- (ix) (Dominated convergence in probability) If
converges to
.
Exercise 3 Let
- (i) Suppose that there is a random variable
. Show that
- (ii) Suppose that the
such that
almost surely).
We can now state the weak and strong law of large numbers, in the model case of iid random variables.
Theorem 4 (Law of large numbers, model case) Let
be an iid sequence of copies of an absolutely integrable random variable
- (i) (Weak law of large numbers) The random variables
- (ii) (Strong law of large numbers) The random variables
Informally: if 
It is instructive to compare the law of large numbers with what one can obtain from the Kolmogorov zero-one law, discussed in Notes 2. Observe that if the 




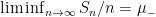

The law of large numbers asserts, roughly speaking, that the theoretical expectation 
There are several ways to prove the law of large numbers (in both forms). One basic strategy is to use the moment method – controlling statistics such as 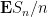

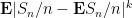


For the strong law of large numbers, one can also use methods relating to the theory of martingales, such as stopping time arguments and maximal inequalities; we present some classical arguments of Kolmogorov in this regard.
Read the rest of this entry »
In the previous set of notes, we constructed the measure-theoretic notion of the Lebesgue integral, and used this to set up the probabilistic notion of expectation on a rigorous footing. In this set of notes, we will similarly construct the measure-theoretic concept of a product measure (restricting to the case of probability measures to avoid unnecessary technicalities), and use this to set up the probabilistic notion of independence on a rigorous footing. (To quote Durrett: “measure theory ends and probability theory begins with the definition of independence.”) We will be able to take virtually any collection of random variables (or probability distributions) and couple them together to be independent via the product measure construction, though for infinite products there is the slight technicality (a requirement of the Kolmogorov extension theorem) that the random variables need to range in standard Borel spaces. This is not the only way to couple together such random variables, but it is the simplest and the easiest to compute with in practice, as we shall see in the next few sets of notes.
Read the rest of this entry »
In Notes 0, we introduced the notion of a measure space 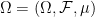
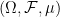




- Given events
, we defined the conjunction
, the disjunction
, and the complement
. For countable families
of events, we similarly defined
and
. We also defined the empty event
and the sure event
, and what it meant for two events to be equal.
- Given random variables
respectively, and a measurable function
, we defined the random variable
in range
. (As the special case
of this, every deterministic element
of
, we similarly defined the event
. Conversely, given an event
. Finally, we defined what it meant for two random variables to be equal.
- Given an event
.
These operations obey various axioms; for instance, the boolean operations on events obey the axioms of a Boolean algebra, and the probabilility function 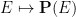
It turns out that almost all of the other operations on random events and variables we need can be constructed in terms of the above basic operations. In particular, this allows one to safely extend the sample space in probability theory whenever needed, provided one uses an extension that respects the above basic operations; this is an important operation when one needs to add new sources of randomness to an existing system of events and random variables, or to couple together two separate such systems into a joint system that extends both of the original systems. We gave a simple example of such an extension in the previous notes, but now we give a more formal definition:
Definition 1 Suppose that we are using a probability space
, together with a measurable map
(sometimes called the factor map) which is probability-preserving in the sense that
for all
. (Caution: this does not imply that
for all
– why not?)
An event
in the extended sample space
. Similarly, a random variable
in
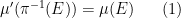
Thus, for instance, the sample space 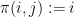
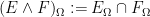
or via the extension

The two definitions are consistent with each other, thanks to the obvious set-theoretic identity
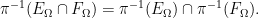
Similarly, the assumption (1) is precisely what is needed to ensure that the probability 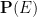
Remark 2 There is one minor exception to this general rule if we do not impose the additional requirement that the factor map
is surjective. Namely, for non-surjective
are unequal in the original sample space model, but become equal in the extension (and similarly for random variables), although the converse never happens (events that are equal in the original sample space always remain equal in the extension). For instance, let
with
and
, and let
with
, and non-surjective factor map
. Then the event modeled by
in
Roughly speaking, one can define probability theory as the study of those properties of random events and random variables that are model-independent in the sense that they are preserved by extensions. For instance, the cardinality 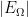



On the other hand, the supremum 
![{[-\infty,+\infty]}](https://s0.wp.com/latex.php?latex=%7B%5B-%5Cinfty%2C%2B%5Cinfty%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)



we thus see that one can completely specify 
In this set of notes, we will define some further important operations on scalar random variables, in particular the expectation of these variables. In the sample space models, expectation corresponds to the notion of integration on a measure space. As we will need to use both expectation and integration in this course, we will thus begin by quickly reviewing the basics of integration on a measure space, although we will then translate the key results of this theory into probabilistic language.
As the finer details of the Lebesgue integral construction are not the core focus of this probability course, some of the details of this construction will be left to exercises. See also Chapter 1 of Durrett, or these previous blog notes, for a more detailed treatment.
Starting this week, I will be teaching an introductory graduate course (Math 275A) on probability theory here at UCLA. While I find myself using probabilistic methods routinely nowadays in my research (for instance, the probabilistic concept of Shannon entropy played a crucial role in my recent paper on the Chowla and Elliott conjectures, and random multiplicative functions similarly played a central role in the paper on the Erdos discrepancy problem), this will actually be the first time I will be teaching a course on probability itself (although I did give a course on random matrix theory some years ago that presumed familiarity with graduate-level probability theory). As such, I will be relying primarily on an existing textbook, in this case Durrett’s Probability: Theory and Examples. I still need to prepare lecture notes, though, and so I thought I would continue my practice of putting my notes online, although in this particular case they will be less detailed or complete than with other courses, as they will mostly be focusing on those topics that are not already comprehensively covered in the text of Durrett. Below the fold are my first such set of notes, concerning the classical measure-theoretic foundations of probability. (I wrote on these foundations also in this previous blog post, but in that post I already assumed that the reader was familiar with measure theory and basic probability, whereas in this course not every student will have a strong background in these areas.)
Note: as this set of notes is primarily concerned with foundational issues, it will contain a large number of pedantic (and nearly trivial) formalities and philosophical points. We dwell on these technicalities in this set of notes primarily so that they are out of the way in later notes, when we work with the actual mathematics of probability, rather than on the supporting foundations of that mathematics. In particular, the excessively formal and philosophical language in this set of notes will not be replicated in later notes.

Recent Comments