
You are currently browsing the category archive for the ‘math.DG’ category.
I was pleased to learn this week that the 2019 Abel Prize was awarded to Karen Uhlenbeck. Uhlenbeck laid much of the foundations of modern geometric PDE. One of the few papers I have in this area is in fact a joint paper with Gang Tian extending a famous singularity removal theorem of Uhlenbeck for four-dimensional Yang-Mills connections to higher dimensions. In both these papers, it is crucial to be able to construct “Coulomb gauges” for various connections, and there is a clever trick of Uhlenbeck for doing so, introduced in another important paper of hers, which is absolutely critical in my own paper with Tian. Nowadays it would be considered a standard technique, but it was definitely not so at the time that Uhlenbeck introduced it.
Suppose one has a smooth connection 
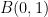


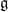

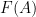
![\displaystyle F(A)_{\alpha \beta} = \partial_\alpha A_\beta - \partial_\beta A_\alpha + [A_\alpha,A_\beta]. \ \ \ \ \ (1)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+F%28A%29_%7B%5Calpha+%5Cbeta%7D+%3D+%5Cpartial_%5Calpha+A_%5Cbeta+-+%5Cpartial_%5Cbeta+A_%5Calpha+%2B+%5BA_%5Calpha%2CA_%5Cbeta%5D.+%5C+%5C+%5C+%5C+%5C+%281%29&bg=ffffff&fg=000000&s=0&c=20201002)
It is natural to place the curvature in a scale-invariant space such as 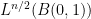
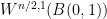
There is a basic obstruction provided by gauge invariance. For any smooth gauge 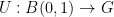
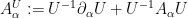
and then a brief calculation shows that the curvature is conjugated to
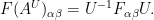
This gauge symmetry does not affect the 
However, one can hope to overcome this problem by gauge fixing: perhaps if 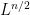
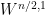
To make the problem elliptic, one can try to impose the Coulomb gauge condition

(also known as the Lorenz gauge or Hodge gauge in various papers), together with a natural boundary condition on 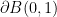
![\displaystyle \partial^\alpha F(A)_{\alpha \beta} = \Delta A_\beta + \partial^\alpha [A_\alpha,A_\beta] \ \ \ \ \ (3)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cpartial%5E%5Calpha+F%28A%29_%7B%5Calpha+%5Cbeta%7D+%3D+%5CDelta+A_%5Cbeta+%2B+%5Cpartial%5E%5Calpha+%5BA_%5Calpha%2CA_%5Cbeta%5D+%5C+%5C+%5C+%5C+%5C+%283%29&bg=ffffff&fg=000000&s=0&c=20201002)
and if one could somehow ignore the nonlinear term ![{\partial^\alpha [A_\alpha,A_\beta]}](https://s0.wp.com/latex.php?latex=%7B%5Cpartial%5E%5Calpha+%5BA_%5Calpha%2CA_%5Cbeta%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
The problem is then how to handle the nonlinear term. If we already knew that
Uhlenbeck’s clever way out of this circularity is a textbook example of what is now known as a “continuity” argument. Instead of trying to work just with the original connection 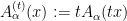
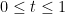


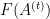
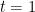

![{t \in [0,1]}](https://s0.wp.com/latex.php?latex=%7Bt+%5Cin+%5B0%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

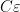

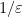
![{t' \in [0,1]}](https://s0.wp.com/latex.php?latex=%7Bt%27+%5Cin+%5B0%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)

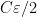
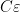
![{[0,1]}](https://s0.wp.com/latex.php?latex=%7B%5B0%2C1%5D%7D&bg=ffffff&fg=000000&s=0&c=20201002)
One of the lessons I drew from this example is to not be deterred (especially in PDE) by an argument seeming to be circular; if the argument is still sufficiently “nontrivial” in nature, it can often be modified into a usefully non-circular argument that achieves what one wants (possibly under an additional qualitative hypothesis, such as a continuity or smoothness hypothesis).
These lecture notes are a continuation of the 254A lecture notes from the previous quarter.
We consider the Euler equations for incompressible fluid flow on a Euclidean space 
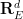
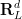






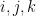
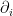


In Eulerian coordinates, the Euler equations read


where 
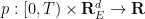
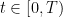
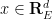
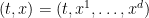


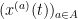



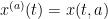

We will refer to the coordinates
In view of this, it is natural to ask whether there is an alternate way to formulate the continuum limit of incompressible inviscid fluids, by using a continuous version 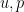
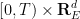

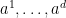
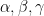
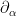
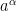
Given a smooth and bounded velocity field 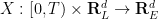

in view of (2), this describes the trajectory (in 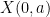
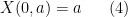
for 
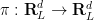
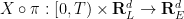
Despite the popularity of the initial condition (4), we will try to keep conceptually separate the Eulerian space 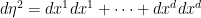
Exercise 1 Let
- If
is a smooth map, show that there exists a unique smooth trajectory map
for all
- Show that if
is a diffeomorphism and
is also a diffeomorphism.
Remark 2 The first of the Euler equations (1) can now be written in the form
which can be viewed as a continuous limit of Newton’s first law
.
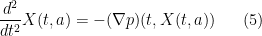
Call a diffeomorphism 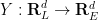
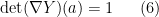
for all 


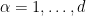






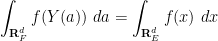
for all 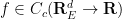
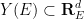

The divergence-free condition 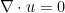

Lemma 3 Let
is volume-preserving for all
Proof: Since 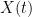

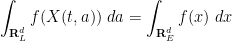
for all
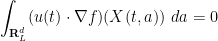
for all
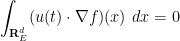
which by integration by parts gives

for all
To prove the converse implication, it is convenient to introduce the labels map 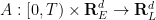

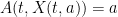
for all 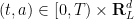
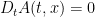
where 
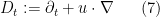
acting on functions on

for any test function 
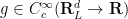
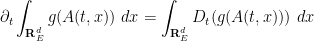
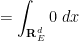
and hence

for any 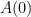
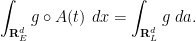
Thus 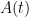

Exercise 4 Let
be a continuously differentiable map from the time interval
to the general linear group
of invertible
and use this and (6) to give an alternate proof of Lemma 3 that does not involve any integration in space.
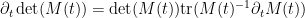
Remark 5 One can view the use of Lagrangian coordinates as an extension of the method of characteristics. Indeed, from the chain rule we see that for any smooth function
of Eulerian spacetime, one has
and hence any transport equation that in Eulerian coordinates takes the form
for smooth functions
of Eulerian spacetime is equivalent to the ODE
where
are the smooth functions of Lagrangian spacetime defined by
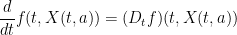



In this set of notes we recall some basic differential geometry notation, particularly with regards to pullbacks and Lie derivatives of differential forms and other tensor fields on manifolds such as
Remark 6 One can also write the Navier-Stokes equations in Lagrangian coordinates, but the equations are not expressed in a favourable form in these coordinates, as the Laplacian
appearing in the viscosity term becomes replaced with a time-varying Laplace-Beltrami operator. As such, we will not discuss the Lagrangian coordinate formulation of Navier-Stokes here.
Previous set of notes: Notes 4. Next set of notes: 246B Notes 1.
In the previous set of notes we introduced the notion of a complex diffeomorphism 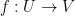
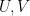

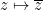
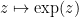

Lemma 1 (Holomorphicity and harmonicity are conformal invariants) Let
be a complex diffeomorphism between two Riemann surfaces
- (i) If
is a function to another Riemann surface
, then
is holomorphic if and only if
is holomorphic.
- (ii) If
is a function, then
is harmonic.
Proof: Part (i) is immediate since the composition of two holomorphic functions is holomorphic. For part (ii), observe that if 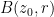

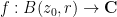
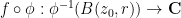

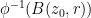
Exercise 2 Establish Lemma 1(ii) by direct calculation, avoiding the use of holomorphic functions. (Hint: the calculations are cleanest if one uses Wirtinger derivatives, as per Exercise 27 of Notes 1.)
Exercise 3 Let
be a point in
be a natural number, and let
be holomorphic. Show that
if and only if
has a zero (resp. a pole) of order
From Lemma 1(ii) we can now define the notion of a harmonic function 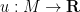

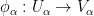
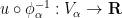

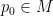

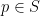

In view of Lemma 1, it is thus natural to ask which Riemann surfaces are complex diffeomorphic to each other, and more generally to understand the space of holomorphic maps from one given Riemann surface to another. We will initially focus attention on three important model Riemann surfaces:
- (i) (Elliptic model) The Riemann sphere
;
- (ii) (Parabolic model) The complex plane
- (iii) (Hyperbolic model) The unit disk
.
The designation of these model Riemann surfaces as elliptic, parabolic, and hyperbolic comes from Riemannian geometry, where it is natural to endow each of these surfaces with a constant curvature Riemannian metric which is positive, zero, or negative in the elliptic, parabolic, and hyperbolic cases respectively. However, we will not discuss Riemannian geometry further here.
All three model Riemann surfaces are simply connected, but none of them are complex diffeomorphic to any other; indeed, there are no non-constant holomorphic maps from the Riemann sphere to the plane or the disk, nor are there any non-constant holomorphic maps from the plane to the disk (although there are plenty of holomorphic maps going in the opposite directions). The complex automorphisms (that is, the complex diffeomorphisms from a surface to itself) of each of the three surfaces can be classified explicitly. The automorphisms of the Riemann sphere turn out to be the Möbius transformations 
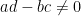

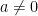

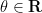
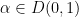
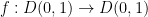

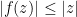
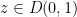
It is a beautiful and fundamental fact in complex analysis that these three model Riemann surfaces are in fact an exhaustive list of the simply connected Riemann surfaces, up to complex diffeomorphism. More precisely, we have the Riemann mapping theorem and the uniformisation theorem:
Theorem 4 (Riemann mapping theorem) Let
Theorem 5 (Uniformisation theorem) Let
As we shall see, every connected Riemann surface can be viewed as the quotient of its simply connected universal cover by a discrete group of automorphisms known as deck transformations. This in principle gives a complete classification of Riemann surfaces up to complex diffeomorphism, although the situation is still somewhat complicated in the hyperbolic case because of the wide variety of discrete groups of automorphisms available in that case.
We will prove the Riemann mapping theorem in these notes, using the elegant argument of Koebe that is based on the Schwarz lemma and Montel’s theorem (Exercise 58 of Notes 4). The uniformisation theorem is however more difficult to establish; we discuss some components of a proof (based on the Perron method of subharmonic functions) here, but stop short of providing a complete proof.
The above theorems show that it is in principle possible to conformally map various domains into model domains such as the unit disk, but the proofs of these theorems do not readily produce explicit conformal maps for this purpose. For some domains we can just write down a suitable such map. For instance:
Exercise 6 (Cayley transform) Let
be the upper half-plane. Show that the Cayley transform
, defined by
is a complex diffeomorphism from the upper half-plane
to the disk
given by
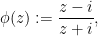

Exercise 7 Show that for any real numbers
, the strip
is complex diffeomorphic to the disk
Exercise 8 Show that for any real numbers
, the strip
is complex diffeomorphic to the disk
.)
We will discuss some other explicit conformal maps in this set of notes, such as the Schwarz-Christoffel maps that transform the upper half-plane
Read the rest of this entry »
Previous set of notes: Notes 3. Next set of notes: Notes 5.
In the previous set of notes we saw that functions 

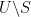
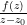



Singularities come in varying levels of “badness” in complex analysis. The least harmful type of singularity is the removable singularity – a point 



After removable singularities, the mildest form of singularity one can encounter is that of a pole – an isolated singularity 

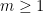

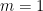
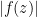

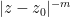

Unfortunately, there are isolated singularities that are neither removable or poles, and are known as essential singularities. A typical example is the function 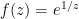
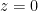
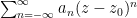
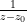

Finally, there are the non-isolated singularities. Little can be said about these singularities in general (for instance, the residue theorem does not directly apply in the presence of such singularities), but certain types of non-isolated singularities are still relatively easy to understand. One particularly common example of such non-isolated singularity arises when trying to invert a non-injective function, such as the complex exponential 
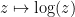
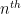
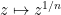
Throughout this post we shall always work in the smooth category, thus all manifolds, maps, coordinate charts, and functions are assumed to be smooth unless explicitly stated otherwise.
A (real) manifold
Theorem 1 (Whitney embedding theorem) Let
from
In fact, if 

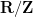

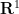
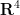
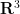

A significant strengthening of the Whitney embedding theorem is (a special case of) the Nash embedding theorem:
Theorem 2 (Nash embedding theorem) Let
be a compact Riemannian manifold. Then there exists a isometric embedding
In order to obtain the isometric embedding, the dimension
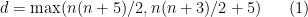
is attained, which I believe is still the record for large 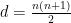
I recently had the need to invoke the Nash embedding theorem to establish a blowup result for a nonlinear wave equation, which motivated me to go through the proof of the theorem more carefully. Below the fold I give a proof of the theorem that does not attempt to give an optimal value of 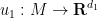
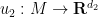
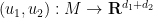
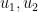
In preparing these notes, I found the articles of Deane Yang and of Siyuan Lu to be helpful.
In addition to the Fields medallists mentioned in the previous post, the IMU also awarded the Nevanlinna prize to Subhash Khot, the Gauss prize to Stan Osher (my colleague here at UCLA!), and the Chern medal to Phillip Griffiths. Like I did in 2010, I’ll try to briefly discuss one result of each of the prize winners, though the fields of mathematics here are even further from my expertise than those discussed in the previous post (and all the caveats from that post apply here also).
Subhash Khot is best known for his Unique Games Conjecture, a problem in complexity theory that is perhaps second in importance only to the 

My colleague Stan Osher has worked in many areas of applied mathematics, ranging from image processing to modeling fluids for major animation studies such as Pixar or Dreamworks, but today I would like to talk about one of his contributions that is close to an area of my own expertise, namely compressed sensing. One of the basic reconstruction problem in compressed sensing is the basis pursuit problem of finding the vector 
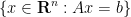

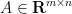

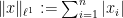
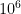

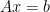
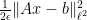
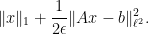
This functional is more convex, and is over a computationally simpler domain 
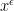

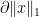



then some simple convexity considerations reveal that the minimiser to this new problem will match the minimiser
With Yin, Goldfarb and Darbon, Osher introduced a Bregman iteration method in which one solves for 
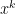
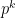

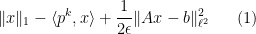
and then updates 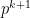
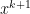
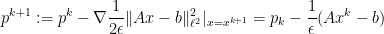
(note upon taking the first variation of (1) that
Phillip Griffiths has made many contributions to complex, algebraic and differential geometry, and I am not qualified to describe most of these; my primary exposure to his work is through his text on algebraic geometry with Harris, but as excellent though that text is, it is not really representative of his research. But I thought I would mention one cute result of his related to the famous Nash embedding theorem. Suppose that one has a smooth 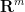
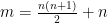
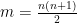


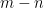
Let 



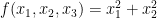
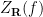
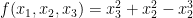
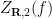
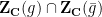
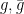
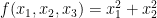
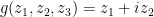
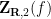
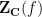
The surface 
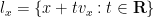
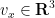

for all 
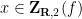
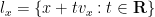
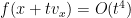
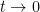 , or equivalently that
, or equivalently that 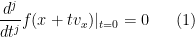
for 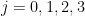
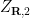
Theorem 1 (Monge-Cayley-Salmon theorem) Let
non-empty. Suppose that a Zariski dense set of points in
Among other things, this theorem was used in the celebrated result of Guth and Katz that almost solved the Erdos distance problem in two dimensions, as discussed in this previous blog post. Vanishing to third order is necessary: observe that in a surface of negative curvature, such as the saddle 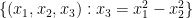

The original proof of the Monge-Cayley-Salmon theorem is not easily accessible and not written in modern language. A modern proof of this theorem (together with substantial generalisations, for instance to higher dimensions) is given by Landsberg; the proof uses the machinery of modern algebraic geometry. The purpose of this post is to record an alternate proof of the Monge-Cayley-Salmon theorem based on classical differential geometry (in particular, the notion of torsion of a curve) and basic ODE methods (in particular, Gronwall’s inequality and the Picard existence theorem). The idea is to “integrate” the lines 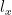

Update: Janos Kollar has informed me that the above theorem was essentially known to Monge in 1809; see his recent arXiv note for more details.
I thank Larry Guth and Micha Sharir for conversations leading to this post.
In this set of notes, we describe the basic analytic structure theory of Lie groups, by relating them to the simpler concept of a Lie algebra. Roughly speaking, the Lie algebra encodes the “infinitesimal” structure of a Lie group, but is a simpler object, being a vector space rather than a nonlinear manifold. Nevertheless, thanks to the fundamental theorems of Lie, the Lie algebra can be used to reconstruct the Lie group (at a local level, at least), by means of the exponential map and the Baker-Campbell-Hausdorff formula. As such, the local theory of Lie groups is completely described (in principle, at least) by the theory of Lie algebras, which leads to a number of useful consequences, such as the following:
- (Local Lie implies Lie) A topological group
- (Uniqueness of Lie structure) A topological group has at most one smooth structure on it that makes it Lie.
- (Weak regularity implies strong regularity, I) Lie groups are automatically real analytic. (In fact one only needs a “local
” regularity on the group structure to obtain real analyticity.)
- (Weak regularity implies strong regularity, II) A continuous homomorphism from one Lie group to another is automatically smooth (and real analytic).
The connection between Lie groups and Lie algebras also highlights the role of one-parameter subgroups of a topological group, which will play a central role in the solution of Hilbert’s fifth problem.
We note that there is also a very important algebraic structure theory of Lie groups and Lie algebras, in which the Lie algebra is split into solvable and semisimple components, with the latter being decomposed further into simple components, which can then be completely classified using Dynkin diagrams. This classification is of fundamental importance in many areas of mathematics (e.g. representation theory, arithmetic geometry, and group theory), and many of the deeper facts about Lie groups and Lie algebras are proven via this classification (although in such cases it can be of interest to also find alternate proofs that avoid the classification). However, it turns out that we will not need this theory in this course, and so we will not discuss it further here (though it can of course be found in any graduate text on Lie groups and Lie algebras).
Over the past few months or so, I have been brushing up on my Lie group theory, as part of my project to fully understand the theory surrounding Hilbert’s fifth problem. Every so often, I encounter a basic fact in Lie theory which requires a slightly non-trivial “trick” to prove; I am recording two of them here, so that I can find these tricks again when I need to.
The first fact concerns the exponential map 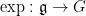
It is natural to ask whether the exponential map is globally a homeomorphism, and not just locally: in particular, whether the exponential map remains both injective and surjective. For instance, this is the case for connected, simply connected, nilpotent Lie groups (as can be seen from the Baker-Campbell-Hausdorff formula.)
The circle group 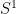
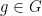
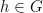
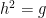
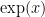
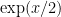
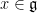

in the connected Lie group 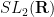
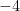
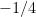
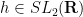
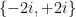
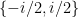


However, there is an important case where surjectivity is recovered:
Proposition 1 If
Proof: The idea here is to relate the exponential map in Lie theory to the exponential map in Riemannian geometry. We first observe that every compact Lie group 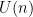
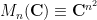

As
Remark 1 While it is quite nice to see Riemannian geometry come in to prove this proposition, I am curious to know if there is any other proof of surjectivity for compact connected Lie groups that does not require explicit introduction of Riemannian geometry concepts.
The other basic fact I learned recently concerns the algebraic nature of Lie groups and Lie algebras. An important family of examples of Lie groups are the algebraic groups – algebraic varieties with a group law given by algebraic maps. Given that one can always automatically upgrade the smooth structure on a Lie group to analytic structure (by using the Baker-Campbell-Hausdorff formula), it is natural to ask whether one can upgrade the structure further to an algebraic structure. Unfortunately, this is not always the case. A prototypical example of this is given by the one-parameter subgroup
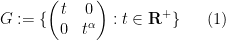
of 


This is not a true counterexample to the claim that every Lie group can be given the structure of an algebraic group, because one can give
Proposition 2 There exists a Lie group
Proof: We use an example from the text of Tauvel and Yu (that I found via this MathOverflow posting). We consider the subgroup
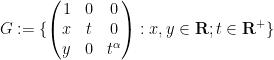
of 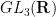
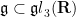
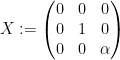
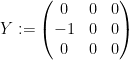
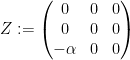
with the Lie bracket given by
![\displaystyle [Y,X] = -Y; [Z,X] = -\alpha Z; [Y,Z] = 0.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5BY%2CX%5D+%3D+-Y%3B+%5BZ%2CX%5D+%3D+-%5Calpha+Z%3B+%5BY%2CZ%5D+%3D+0.&bg=ffffff&fg=000000&s=0&c=20201002)
As such, we see that if we use the basis 
If 
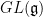
A slight modification of the same argument also shows that not every Lie algebra is algebraic, in the sense that it is isomorphic to a Lie algebra of an algebraic group. (However, there are important classes of Lie algebras that are automatically algebraic, such as nilpotent or semisimple Lie algebras.)
Hilbert’s fifth problem asks to clarify the extent that the assumption on a differentiable or smooth structure is actually needed in the theory of Lie groups and their actions. While this question is not precisely formulated and is thus open to some interpretation, the following result of Gleason and Montgomery-Zippin answers at least one aspect of this question:
Theorem 1 (Hilbert’s fifth problem) Let
Theorem 1 can be viewed as an application of the more general structural theory of locally compact groups. In particular, Theorem 1 can be deduced from the following structural theorem of Gleason and Yamabe:
Theorem 2 (Gleason-Yamabe theorem) Let
of
of
is isomorphic to a Lie group.
The deduction of Theorem 1 from Theorem 2 proceeds using the Brouwer invariance of domain theorem and is discussed in this previous post. In this post, I would like to discuss the proof of Theorem 2. We can split this proof into three parts, by introducing two additional concepts. The first is the property of having no small subgroups:
Definition 3 (NSS) A topological group
.
An equivalent definition of an NSS group is one which has an open neighbourhood 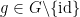
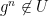
Another useful property is that of having what I will call a Gleason metric:
Definition 4 Let
which generates the topology on
, writing
for
:
- (Escape property) If
, then
.
- (Commutator estimate) If
are such that
, then
where
is the commutator of
![\displaystyle \|[g,h]\| \leq C \|g\| \|h\|, \ \ \ \ \ (1)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5C%7C%5Bg%2Ch%5D%5C%7C+%5Cleq+C+%5C%7Cg%5C%7C+%5C%7Ch%5C%7C%2C+%5C+%5C+%5C+%5C+%5C+%281%29&bg=ffffff&fg=000000&s=0&c=20201002)
For instance, the unitary group 
![\displaystyle \| [g,h] - 1 \|_{op} = \| gh - hg \|_{op}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle++%5C%7C+%5Bg%2Ch%5D+-+1+%5C%7C_%7Bop%7D+%3D+%5C%7C+gh+-+hg+%5C%7C_%7Bop%7D&bg=ffffff&fg=000000&s=0&c=20201002)
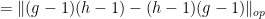
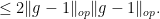
Similarly, any left-invariant Riemannian metric on a (connected) Lie group can be verified to be a Gleason metric. From the escape property one easily sees that all groups with Gleason metrics are NSS; again, we shall see that there is a partial converse.
Remark 1 The escape and commutator properties are meant to capture “Euclidean-like” structure of the group. Other metrics, such as Carnot-Carathéodory metrics on Carnot Lie groups such as the Heisenberg group, usually fail one or both of these properties.
The proof of Theorem 2 can then be split into three subtheorems:
Theorem 5 (Reduction to the NSS case) Let
Theorem 6 (Gleason’s lemma) Let
Theorem 7 (Building a Lie structure) Let
Clearly, by combining Theorem 5, Theorem 6, and Theorem 7 one obtains Theorem 2 (and hence Theorem 1).
Theorem 5 and Theorem 6 proceed by some elementary combinatorial analysis, together with the use of Haar measure (to build convolutions, and thence to build “smooth” bump functions with which to create a metric, in a variant of the analysis used to prove the Birkhoff-Kakutani theorem); Theorem 5 also requires Peter-Weyl theorem (to dispose of certain compact subgroups that arise en route to the reduction to the NSS case), which was discussed previously on this blog.
In this post I would like to detail the final component to the proof of Theorem 2, namely Theorem 7. (I plan to discuss the other two steps, Theorem 5 and Theorem 6, in a separate post.) The strategy is similar to that used to prove von Neumann’s theorem, as discussed in this previous post (and von Neumann’s theorem is also used in the proof), but with the Gleason metric serving as a substitute for the faithful linear representation. Namely, one first gives the space 
The arguments here can be phrased either in the standard analysis setting (using sequences, and passing to subsequences often) or in the nonstandard analysis setting (selecting an ultrafilter, and then working with infinitesimals). In my view, the two approaches have roughly the same level of complexity in this case, and I have elected for the standard analysis approach.
Remark 2 From Theorem 7 we see that a Gleason metric structure is a good enough substitute for smooth structure that it can actually be used to reconstruct the entire smooth structure; roughly speaking, the commutator estimate (1) allows for enough “Taylor expansion” of expressions such as
that one can simulate the fundamentals of Lie theory (in particular, construction of the Lie algebra and the exponential map, and its basic properties. The advantage of working with a Gleason metric rather than a smoother structure, though, is that it is relatively undemanding with regards to regularity; in particular, the commutator estimate (1) is roughly comparable to the imposition

Recent Comments